
On Monday, Google detailed 40 changes it had made to its algorithm, indexing and search results pages in February as part of its Search Quality Highlights series. The post contains an unprecedented amount of detail about what Google has been up to (long may it continue), although as ever there is plenty of scope to read between the lines, get things wrong and generally be infuriated by the fact that you'll end up with more questions than answers by reading it.
That's where I come in. Over at searchenglineland.com Matt McGee has stated "it's impossible to recap the entire Google blog post". Never one to turn down a challenge, I'm going to do just that, one change at a time. Below for your entertainment (or, perhaps, total boredom) are the first 10 changes and my thoughts and speculations on each.
And yes, that does mean you'll have to wait a few days for potentially the most intriguing change of all (hint, it's number 33).
- More coverage for related searches. [launch codename "Fuzhou"] This launch brings in a new data source to help generate the "Searches related to" section, increasing coverage significantly so the feature will appear for more queries. This section contains search queries that can help you refine what you're searching for.
This change refers to the Related Searches links that Google sometimes inserts at the bottom of the first results page. Here's an example from "car insurance":

Logically there aren't that many data sources that Google could use to build related searches. They likely boil down to: User search data (many users search for the keywords in conjunction); Anchor text (many links on the web use the terms in conjunction); Co-occurrence in content (many pages mention the terms together or near each other); User categorisation (from things like the now defunct Google Squared).
Considering user search data is almost certainly the foundation of the feature in the first place, and apparently the new data source increases coverage "significantly", I'd say their new source is either anchor text or page co-occurrence (likely the latter given Google's general direction away from anchor text being important).
In any case, I'm generally sceptical that related searches have much impact on user behaviour, since they appear at the bottom of the page which we know has very little visibility (only around 20% of people will scan to the bottom of the page after searching). Their main effect is to reduce the already paltry traffic to page 2 of the search results still further, so if you in any way rely on traffic from rankings on page 2 you might want to keep an eye out for any new Related Searches appearing for your target keywords.
- Tweak to categorizer for expanded sitelinks. [launch codename "Snippy", project codename "Megasitelinks"] This improvement adjusts a signal we use to try and identify duplicate snippets. We were applying a categorizer that wasn't performing well for our expanded sitelinks, so we've stopped applying the categorizer in those cases. The result is more relevant sitelinks.
- Less duplication in expanded sitelinks. [launch codename "thanksgiving", project codename "Megasitelinks"] We've adjusted signals to reduce duplication in the snippets for expanded sitelinks . Now we generate relevant snippets based more on the page content and less on the query.
Changes 2 & 3 both affect expanded sitelinks and both reduce duplication, so I'm, justified in lumping them together. Since we generally have no impact on whether Google shows mega sitelinks for your brand or not, the main concern for marketers with regards to expanded sitelinks occurs once they have appeared and is generally "how do I control what appears?". Up till now the answer has been a slightly awkward one, since site links have been generated according to a variety of factors including user behaviour and site architecture. This at least makes the picture a little clearer and under control since it's implied you can influence what appears by making the pages you want to appear more unique.
- More consistent thumbnail sizes on results page. We've adjusted the thumbnail size for most image content appearing on the results page, providing a more consistent experience across result types, and also across mobile and tablet. The new sizes apply to rich snippet results for recipes and applications, movie posters, shopping results, book results, news results and more.
Okay, I'm genuinely stumped for anything insightful to say about this. Move along, nothing to see here...
- More locally relevant predictions in YouTube. [project codename "Suggest"] We've improved the ranking for predictions in YouTube to provide more locally relevant queries. For example, for the query [lady gaga in ] performed on the US version of YouTube, we might predict [lady gaga in times square], but for the same search performed on the Indian version of YouTube, we might predict [lady gaga in India].
Note that Google already does this on the main search engine, depending on whether I use Google.com or Google.co.uk when typing in "hotels in..." I either get suggestions for London, Bath and York, or Vegas, New Orleans and Atlantic City. It makes sense that Google should port that tech over to YouTube, especially now that "YouTube" has replaced "Video" in the top navigation bar at Google making it even more obvious that YouTube is video search.

I would like to see Google implementing some smarter method of determining my location. During casual use I often end up searching Google.com (indeed, Google.com has a respectable market share in the UK) and to present me with suggestions for US hotel locations based solely on this seems more than a little bit lazy.
- More accurate detection of official pages. [launch codename "WRE"] We've made an adjustment to how we detect official pages to make more accurate identifications. The result is that many pages that were previously misidentified as official will no longer be.
Google doesn't visibly label sites as official or unofficial, so this detection of a site as "official" or "unofficial" manifests in the search results as an association between certain sites and brand terms that ensures the SERPs for those brand terms are dominated by brand sites. In addition, when Google does things like displaying a stock quote for a brand it needs to be pretty damn sure it's got the right site!
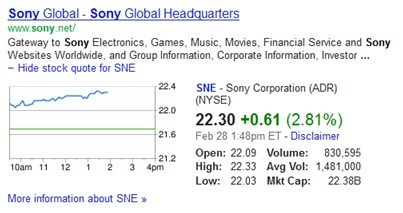
Off the top of my head I can't think of any brand search results pages that aren't accurate, but I'm sure that making this "official site" association more accurate will, somewhere on the planet, be comforting a big brand and creating a headache for an affiliate marketer. So, much like Google's general evolution over the last few years then...
- Refreshed per-URL country information. [Launch codename "longdew", project codename "country-id data refresh"] We updated the country associations for URLs to use more recent data.
There is quite a long list of things that allow search engines to associate a site to a particular location. The primary factor is a sites top level domain (TLD), and I believe this overrides any other consideration. For example, a .co.uk domain is automatically associated to the UK regardless of anything else. Beyond this there are a bunch of less definitive factors: Hosting location; links from other country specific sites; content language; language and region meta tags; webmaster tools settings and so on.
This change suggests one of two things. Either Google has updated its associations between top level domains and countries (not very interesting) or Google also uses less definitive information it finds in the URL (more interesting). For example, Google might be able to tell that www.domain.com/aus/blablabla.html is a page relevant to users in Australia due to the presence of "aus" as a string in the URL (something many SEO's believe Google can't do without other factors).
My advice regarding localisation is if you can't secure or use the correct top level domain for a particular country then you should try and cover as many of the other bases as you can, so here is another potential base to cover.
- Expand the size of our images index in Universal Search. [launch codename "terra", project codename "Images Universal"] We launched a change to expand the corpus of results for which we show images in Universal Search. This is especially helpful to give more relevant images on a larger set of searches.
This is both interesting and important. It tells us that Google has two image indexes, explaining why the image results shown in universal search don't always match the top image results in dedicated image search. In the example below the images in universal search are the 2nd, 4th and 6th ranking images from image search.
Universal search results:

Image search results:
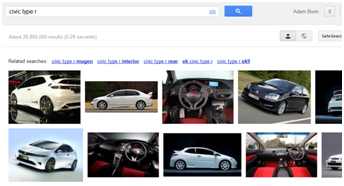
In this highly unscientific study of one, it looks like Google might have an algorithm that identifies less busy imagery or lighter imagery (they've excluded the busier internal images and those with a large expanses of dark background) and hives that off into a separate index for potential display in the main search results. It needs further study but I'm confident suggesting that here because it makes perfect sense for Google to limit the clutter in their main results in this way.
For some queries images can already be very prominent, making it worthwhile to specifically try and gain image search visibility. The description of the change implies that more results can now show images due to the expanded index, but the main takeaway here has to be that the image you choose to target matters much more now we know there is a separate index at play.
- Minor tuning of autocomplete policy algorithms. [project codename "Suggest"] We have a narrow set of policies for autocomplete for offensive and inappropriate terms. This improvement continues to refine the algorithms we use to implement these policies.
This refers to the algorithm that generates the "as you type" suggestions that are often the hilarious subject of articles like this one. Keeping this algorithm up to date is essential for Google's public image. Specifically, the algorithm filters out terms that are pornographic, violent, contain hate speech or lead to sites that infringe copyright, and you can imagine how the web would be up in arms if too many of those terms started appearing.
- "Site:" query update [launch codename "Semicolon", project codename "Dice"] This change improves the ranking for queries using the "site:" operator by increasing the diversity of results.
This change is pretty useful for SEO's, who will often use the site: query to get an idea of the scope of a particular domain, how many sub-domains it might have and its indexation by Google (for the uninitiated, site: followed by a domain name will show - more or less - the indexed pages from that domain, for example site:greenlightdigital.com lists the 2,030 pages Google has indexed on the new Greenlight site).
In my experience to date results from the site: query were often dominated by one sub-domain making it more difficult to gauge how many separate entities you might be dealing with for a prospective project. It's nice to see Google offering a helping hand to SEO's (who, let's face it, are more or less the only people using this query) as by adding more diversity into the results they are showing a higher variety of page types and sub-domains in the same way they do for normal search results.
---
That concludes changes 1-10. Join me soon for the next batch.

