
As of today, Google's "Panda" algorithm update (or "Farmer", as it was originally dubbed by the SEO community) is now live in the UK. This update, designed to improve Google's ability to detect and devalue "low quality content", represents a fairly big step in search engines making the kind of subjective judgements about content that have historically tended to be the preserve of human readers.
I wrote extensively about Panda at the start of March, so this algorithm update and the types of things it includes should come as no surprise. Here's a quick recap of the signals we believed Google Panda took into account or placed more (positive or negative) emphasis on than before:
- Click through rates from the Google search results
- Bounce rates
- Engagement times
- Excessive keyword repetition
- Poor semantic variation and unnatural sentence structure
- Supporting multimedia content (or lack thereof)
For detailed information about any of these signals I'd encourage you to read my previous post.
In part 2 of this blog post I'm going to show you which sites are the big losers from Panda being rolled out in the UK. For now, I'd like to focus on some of the additional information we have about the update from recent announcements and further speculation since March.
Sites blocked by users are now algorithmically affected as well
In addition to the above I'd previously mentioned that Google had checked the results of the shiny new algorithm against data from its "Personal Blocklist" Chrome extension, to find that the sites negatively affected by Panda were broadly comparable to sites that individual Chrome users were blocking from their results anyway. It has now emerged that similar data is being incorporated directly into the algorithm:
Interestingly, these "sites that users block" come not from the Chrome extension but from a piece of functionality in the actual search results that some users have had access to since about mid-March. As Google describes here, when you visit a site from the Google search results and immediately click the back button (i.e. you "bounce" back to the SERPs) you may now see a link that lets you block all results from that site. The logic here being that if you bounce quickly from a site there's a fair chance you won't want to see it appearing in your search results in the future. See the screenshot below for an example of this functionality.
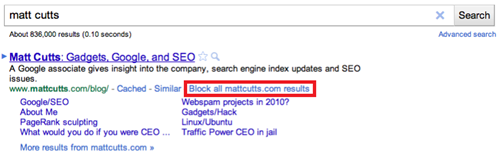
User data is powerful but risky
In the previous post about Google Panda I wrote about how user data would probably need to be used as confirmation of Google's suspicions rather than a signal in its own right:
"However, user click data as a quality signal is highly susceptible to manipulation, which is why it has historically been such a minor part of search engine algorithms. Because of this it's likely that Google only uses this data heavily in combination with other signals.
For example, Google could give a percentage likelihood of a page containing low value content, and then any page that exceeds a certain % threshold might be analysed in terms of its user click data. This keeps such data as confirmation of low quality only, rather than a signal of quality (high or low) in its own right, so it can't be abused by webmasters eager to unleash smart automatic link clicking bots on the Google SERPs."
What's interesting about Google's subsequent announcement about using blocked sites as a signal is that Google using direct user validation of what it already knows or suspects (in this case, it suspects that the site may be of low quality, but wants users to confirm this). In fact it appears that they're actually using user data (blocking a site) to validate other user data (bounce rates) to validate a suspicion about site quality.
These multiple quality checkpoints show that while Google engineers are willing and able to directly interpret user data in their algorithm, they also know that they need to tread carefully because such signals have the potential to be manipulated relatively easily (arguably more easily than links, which have been manipulated for over a decade now).
Other possible Google Panda signals
If you think your site has been affected by Panda, but you're on top of your content quality and users actually seem to like your site, evidenced by high click through rates and user engagement and low bounce rates, there are a couple of other things worth considering that Panda could be looking at that I didn't discuss in my first post.
The first signal is the presence of excessive or overly prominent advertising on a site. Microsoft was recently granted a patent that revealed how Bing could automatically identify advertising on a website by looking for common ad formats (most display advertising conforms to one of half a dozen or so standard dimensions), and things such as the colour of a content block compared to other content on the site (banners typically being designed to stand out from the surrounding content). While the patent is from Microsoft it's safe to assume that Google has similar capabilities, and some industry speculation about Panda has it using this data to judge site quality as well.
Counting ads as a strike against a site could seem quite perverse considering the amount of revenue Google makes from AdSense, the biggest contextual advertising network on the planet. That said, in this instance Google has to balance the conflicting desire to serve users with sites that aren't riddled with advertisements (and thus maintaining market share) while also making money. There is probably a balance here that means Google could, for example, make more money from building long term loyalty in its users than it will lose from devaluing sites that place a lot of advertising prominently above the fold while relegating actual content to the bottom of the page.
The second somewhat related signal is the location and prominence of content on the page. If Google thinks your content is good, but placed in such a manner that most users won't see it (perhaps because it's very far down a page or in a discreet font), it may award you less relevance for that content.
Personally I tend to think that "advertisement overload" and the location and prominence of content on a page would be encompassed by Google looking at bounce rates and user engagement anyway, but you may want to consider these factors for the sake of completeness if your site is suffering from Google Panda.


